
Projects I have been working on
DetGen - Generating controllable traffic micro-structures for model probing
Model validation through careful model probing of particular importance in Cyber-Security. DetGen is a tool we build to produce traffic with controllable characteristics such as the specific conducted activity, transmitted data length, or experienced congestion in order to attach ground truth labels describing the traffic’s computation origin. We use this tool to examine where machine-learning-based intrusion detection models fail to classify traffic correctly and which traffic micro-structures cause this failing.
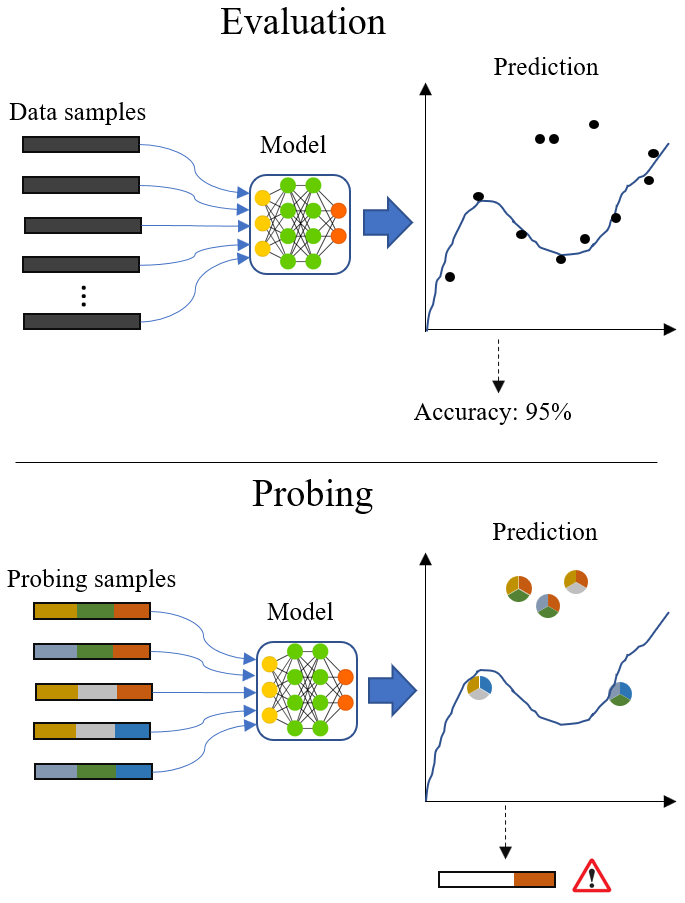
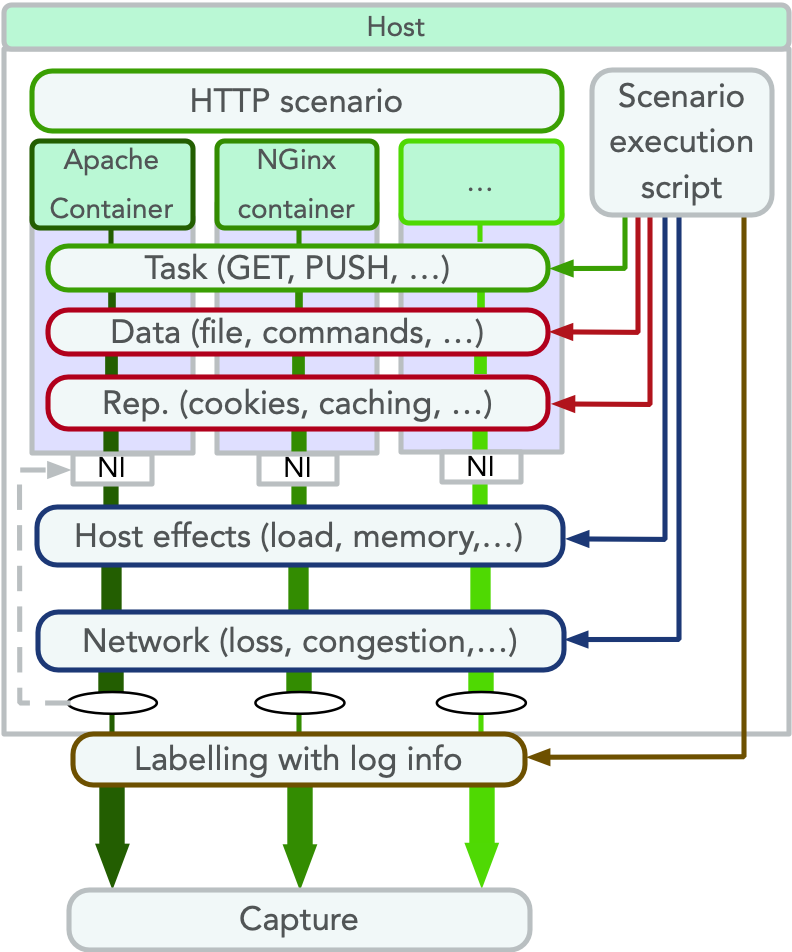
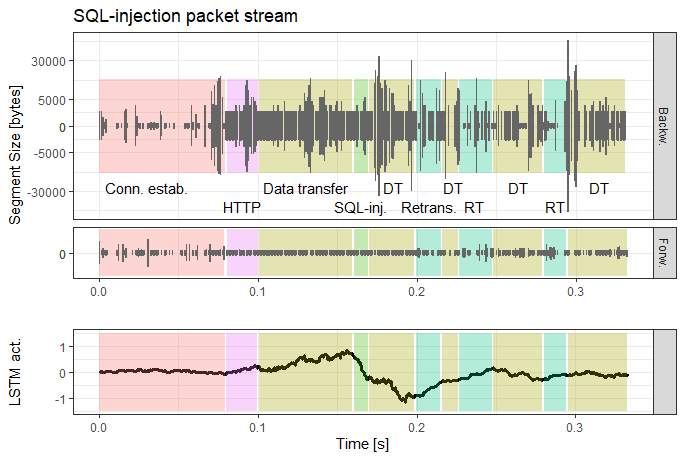
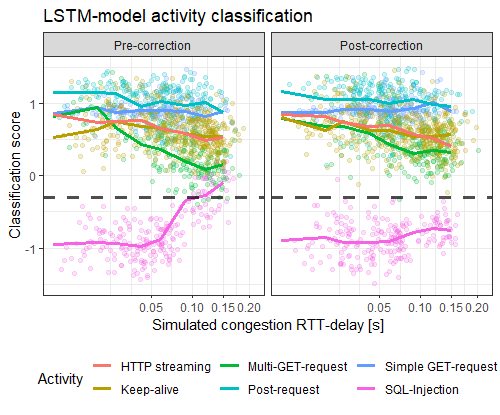
Some use-cases I examined and am currently publishing examine the inability of a LSTM-traffic-classifier to cope with excessive retransmission sequences, or the coherence of encoder-based traffic projection methods.
DetGen is available for researchers to use on GitHub.
Bidirectional LSTMs for access attack detection
In this project, we want to explore how much we can leverage common sequential network flow structures to create a model that detects low-volume access attacks. The underlying idea is that flow sequences corresponding to individual actions such as web-browsing follow very strong and repetitive structures, such as small HTTP-flows normally being followed by larger HTTP-flows.
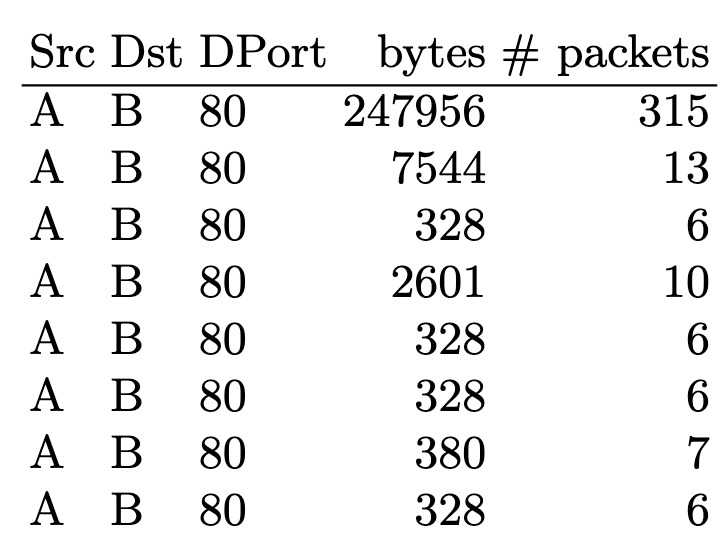
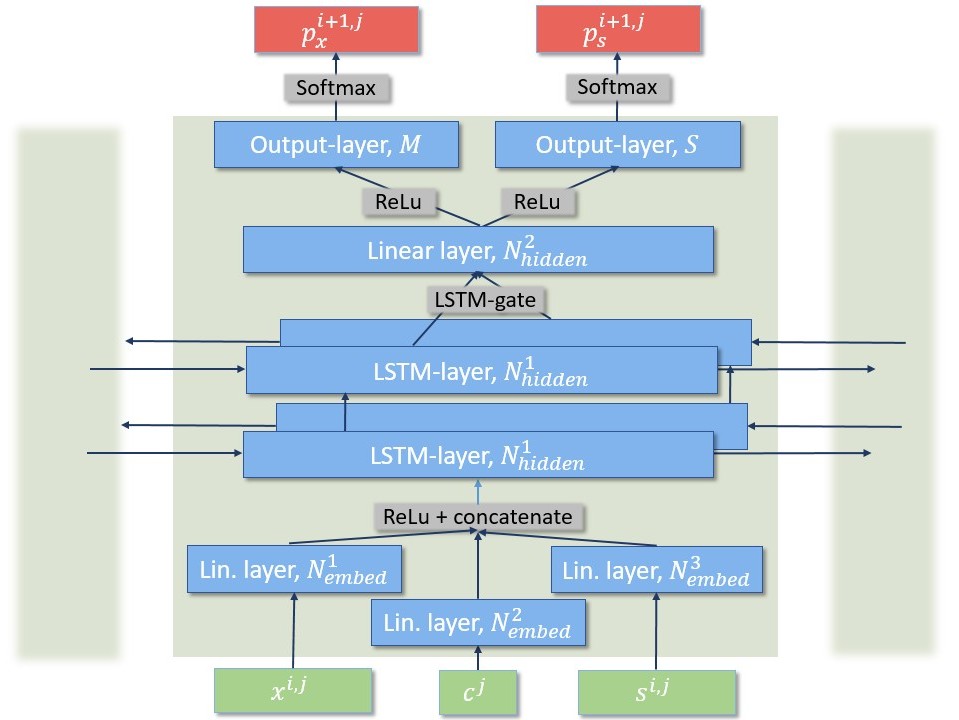
For this, we built a bidirectional LSTM-network with ≈ 10.000 parameters that learns a language model of flow sequences, with flows acting as word tokens according to their destination port, direction, and size. Our consideration is that these structures can help detect low-volume attacks such as Heartbleed or SQL-injections which deviate from these structures by exploiting vulnerabilities.
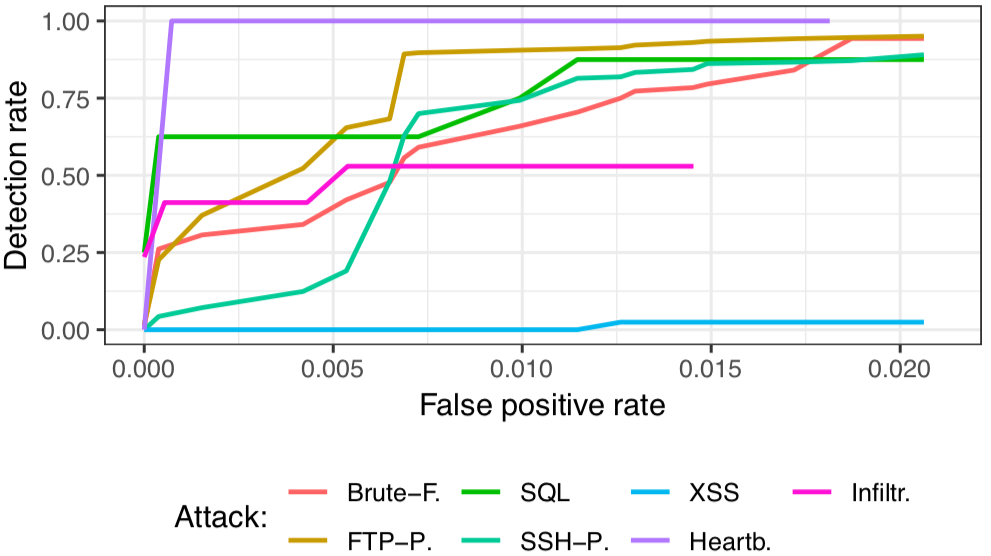
You can find a corresponding implementation here:
CNN for stepping-stone flow correlation
I implemented a deep convolutional Neural Network, inspired by DeepCorr, to correlate connections in a relayed attack. Results were initially very promising, but unfortunately not robust against evasive chaff perturbations, and I have not found a way to overcome this issue. This lead me to perform and publish an evaluation of several stepping-stone detection methods in the presence of chaff, of which none showed sufficient robustness.
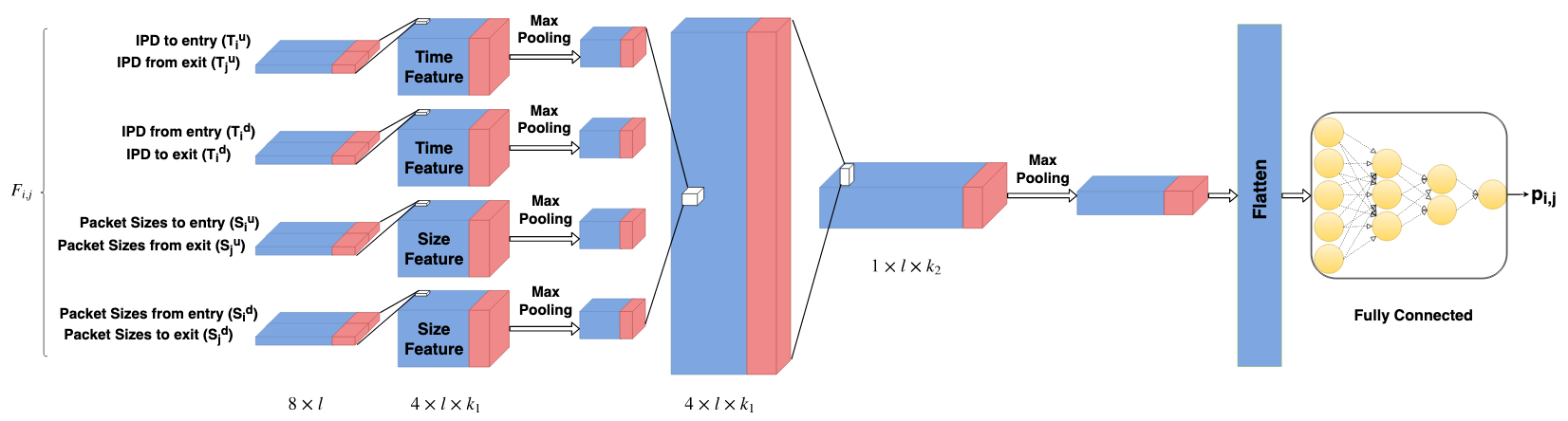
You can find the PyTorch implementation here:
Network traffic activity modelling
For my Master’s thesis, I developed a fast and scalable Bayesian model that extends traditional Markov modulated Poisson processes to capture the non-Poisson-like bursty nature of network traffic. This model identifies different levels of user network activity automatically, which can be used for detecting abnormal usage patterns.
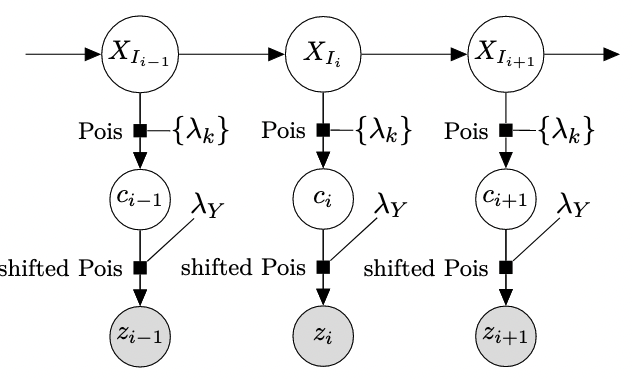
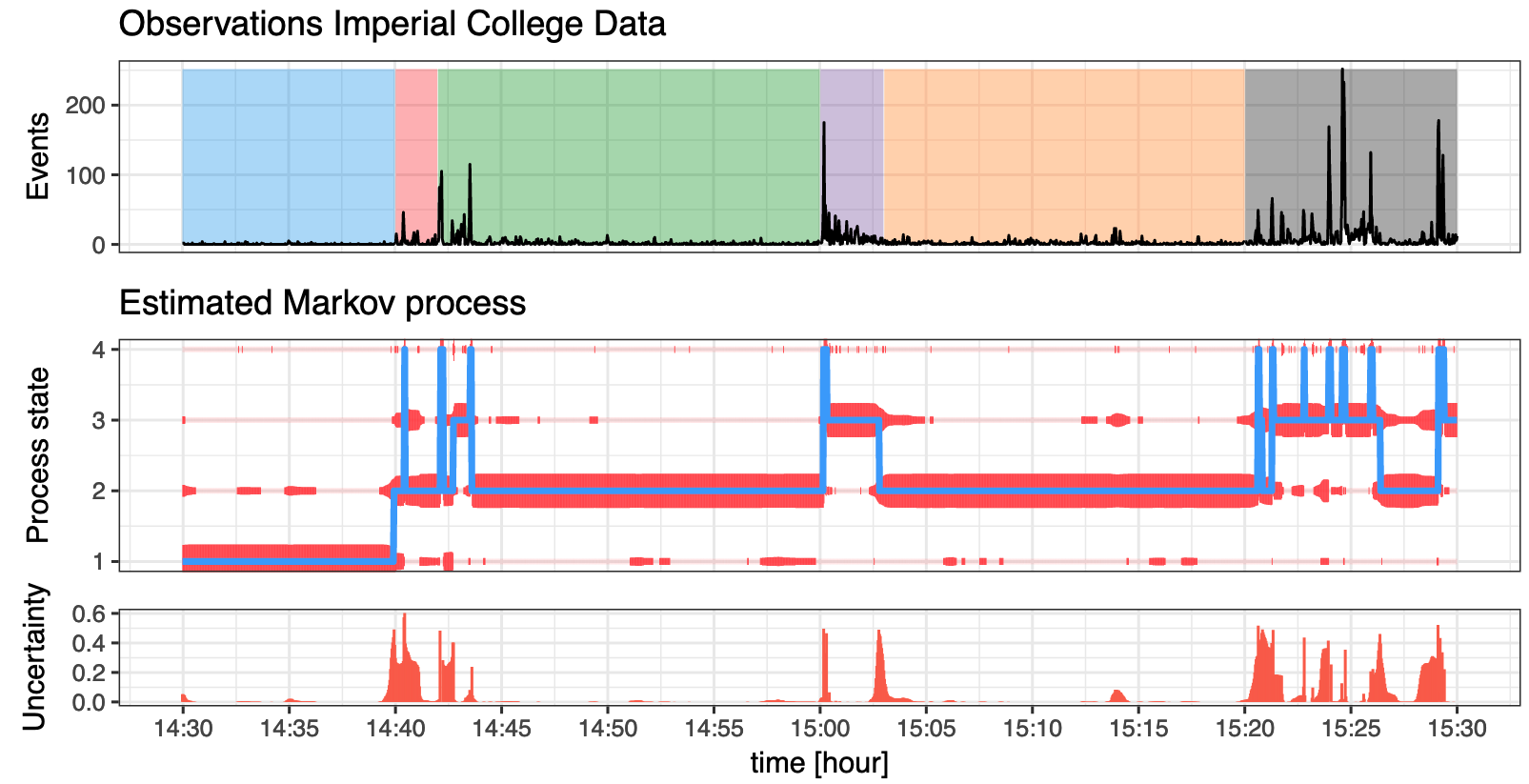
A fast C++-based implementation for R can be found on my GitHub, and on CRAN.